引言
本文基于kubernetes容器平台,分析容器日志采集的前因后果,通过比对EFK和Loki的方案,讨论云原生时代容器日志收集与分析的重点所在。
当服务从裸机部署进入容器时代,容器的强大隔离性与封装性,使得服务的日志变得不稳定。原本裸机运行的程序使用容器运行时,极易由于自动重启,或者自动重建等特性而丢失日志,即便采用了持久化挂载,依然无法根本问题:日志易丢失。对于一个大规模集群而言,完善的日志收集变得越来越重要。
需要采集日志的场景
可以说,基本上所有的程序的日志都应该采集,即使是那些一次性的job等。日志的采集不仅仅是提供给排查bug人员,而且应当作为系统审计的角色存在。收集整个容器平台的所有日志看起来是件多余的事情,毕竟大多数的日志并无用处,但是对于严谨的业务而言,日志是发现问题的最佳途径。
方案一 EFK
就kubernetes平台而言,日志的采集方案比较流行的有EFK,其中E是指elasticsearch,K是指kibana,但是F,有两种说法,一种是指fluentd,另一种是指filebeat;一般分析认为,fluentd相比较于filebeat属于重量级程序。本文任务此处为fluentd。EFK方案的架构很明确,fluentd以DaemonSet形式运行在集群所有节点上,在即指定路径的宿主机日志,例如:/var/log/pods;fluentd采集到日志后,传输到elasticsearch存储,elastic作为一个强大的全文检索引擎,具备良好的并发存储于查询的能力;kibana作为日志的展示工具。
EFK方案实现起来比较成熟,目前多数的方案都是用的是这种,包括k8s官方提供的插件中就有此种方案。但是该方案存在明显的缺陷:
- Elastic Search 的编写语言是Java,其运行时非常占用内存,有时需要把elastic移除到集群外部部署。
- Elastic Search存储的内容虽然比较多,但是大多数并不需要采集。
方案二 Loki
Loki是近期比较流行的k8s日志采集方案。博主认为,说Loki是日志采集方案其实是不准确的。先来看Loki采集的原理:
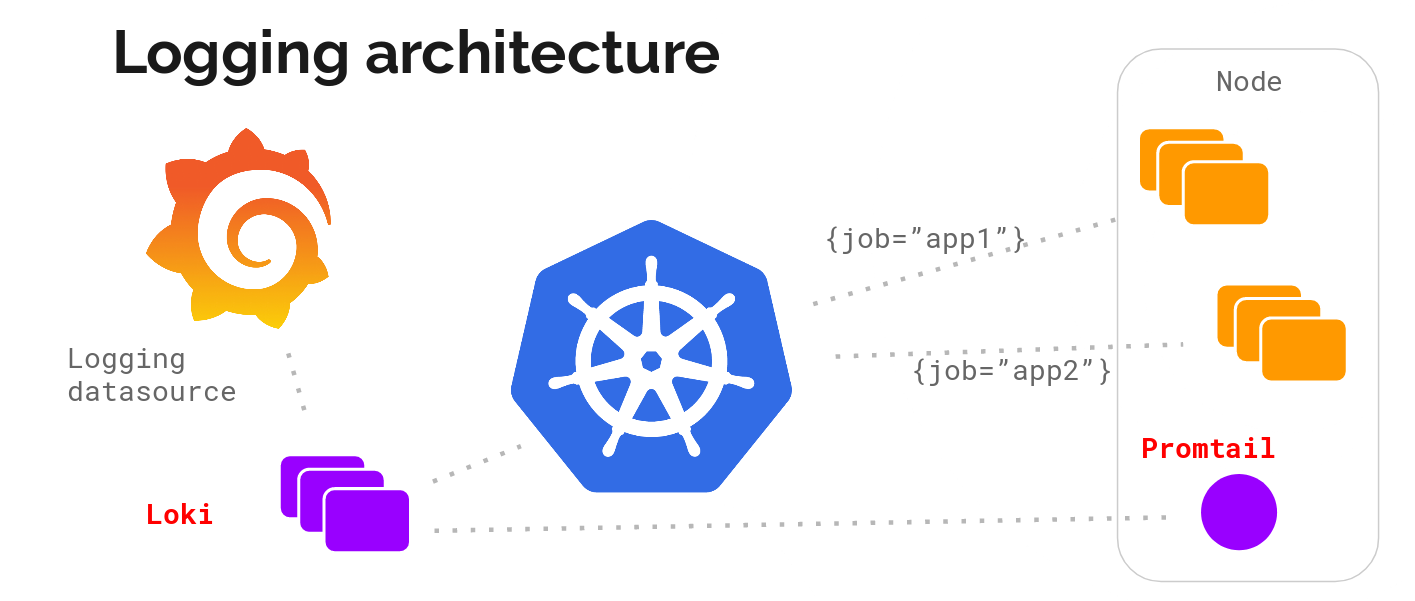
Loki也采用了代理程序与服务端结合的设计:
- Loki 是主服务器,负责存储日志和处理查询
- Promtail 是代理,负责收集日志并将其发送给 Loki 。
- Grafana 用于 UI 展示
Loki的代理程序Promtail部署和fluentd一样,运行在各个节点上。Loki具有以下特性:
- 不对日志做全文索引
- 通过pod标签之类的索引和分组,更加适合k8s环境
- Grafana家族成员,与prometheus语法类似
在Grafana中查询Loki日志的时候,查询出来的是服务检索条件的日志。例如,
查询条件为:{namespace="default",pod="gitlab-webservice-default-679fcdd764-nsl5d"}
表示查询名称空间在default下,pod名叫gitlab-webservice-default-679fcdd764-nsl5d的容器的日志。
不论如何,使用Loki的查询,最后得出来的是面向pod的日志,如果把上述的pod条件去除,则会得出namespace下所有pod的日志。
比较
通过分别使用EFK与Loki,我们可以看出,EFK注重的收集所有的日志,至于如何展示,看使用人员的技术了;而Loki注重的是展示pod的日志,通过简单的语句,筛选出符合要求的日志。
笔者倾向于选择Loki作为容器日志采集方案,原因除了以上之外,还考虑到能否整合Loki与prometheus,实现基于日志采集的告警方案。参见https://github.com/linjinbao666/log-practice.git仓库。